
by Laurie Sullivan @lauriesullivan
Source: www.mediapost.com, February 2024
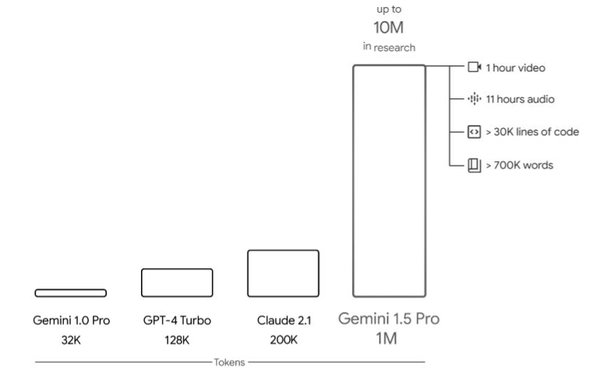
Months after Google made its Gemini AI model public, it is rolling out a new version that can handle several times as much audio, video, and text input as OpenAI’s GPT-4.
Google’s next generation of its Gemini AI technology, Gemini 1.5, demonstrates “dramatic improvements” in several ways, and 1.5 Pro now achieves comparable quality to 1.0 Ultra, while using less computing power.
Demis Hassabis, CEO of Google DeepMind, developed the new model, and introduced it with Alphabet CEO Sundar Pichai in a blog post Thursday on behalf of the Gemini team.
In the post, Hassabis explained how the group is working to optimize the technology, improve latency, reduce computational requirements and enhance the user experience.
He compared the technology’s improved capacity for input “to a person’s working memory” — a topic Hassabis explored years ago as a neuroscientist, according to Wired. “The great thing about these core capabilities is that they unlock sort of ancillary things that the model can do.”
Memory has been a topic of discussion during the past few days, after OpenAI revealed that it is testing an option that allows ChatGPT to retain information from one exchange to the next.
The Memory option is described in a similar way to how search engines and retail sites retain consented first-party information to use in future exchanges of information.
Captify CPO Amelia Waddington said on Thursday that ChatGPT with a memory could prove useful for retail when trying to match one product bought last week for something the consumer searches for today.
Continued advances in next-generation models will open up new possibilities for advertisers as well as developers when it comes to problem solving and enterprises to create, discover and build services using AI.
Gemini Pro is being made available to developers through AI Studio, a sandbox for testing model capabilities, and to a limited number of developers though Google’s Vertex AI cloud platform API.
New tools will help developers use Gemini in their applications, including ways to parse video and audio.
The company also said it is adding new Gemini-powered features to its web-based coding tool, such as ways for AI to debug and test code.
This version of Gemini 1.5 Pro can analyze, classify and summarize large amounts of content within a given prompt. Hassabis provided this example: when given the 402-page transcripts from Apollo 11’s mission to the moon, it can reason about conversations, events and details found across the document.
The technology can perform “highly-sophisticated understanding and reasoning tasks for different modalities, including video.”
When it is given a 44-minute silent Buster Keaton movie, the model can analyze various plot points and events, and even reason about small details in the movie that could easily be missed.
Relevant problem solving has also been improved across longer blocks of code.
When given a prompt with more than 100,000 lines of code, it can better reason across examples, suggest helpful modifications and provide explanations about how different parts of the code work.
{kind=link}